
这是 DeepLearning.ai 微专业的第二门课《改善深层神经网络:超参数调试、正则化以及优化》第一周的课程。
数据集划分
我们通常将数据集划分为训练集 training set,简单交叉验证集(验证集)dev set,测试集 test set。
我们使用不同的模型在训练集上进行训练,使用验证集对训练出的模型进行比较,选出最优的模型。最后使用测试集对模型进行评估。
如果数据集较小,可以根据 60%,20%,20%来划分数据集。如果数据集达到了百万级,那么按照 98%,1%,1%来划分也是可以的。
偏差和方差
我们可以观察模型的拟合情况来判断偏差和方差处于何种状态。
如下图所示,如果模型欠拟合,我们称之为高偏差。如果模型过拟合,则称之为高方差
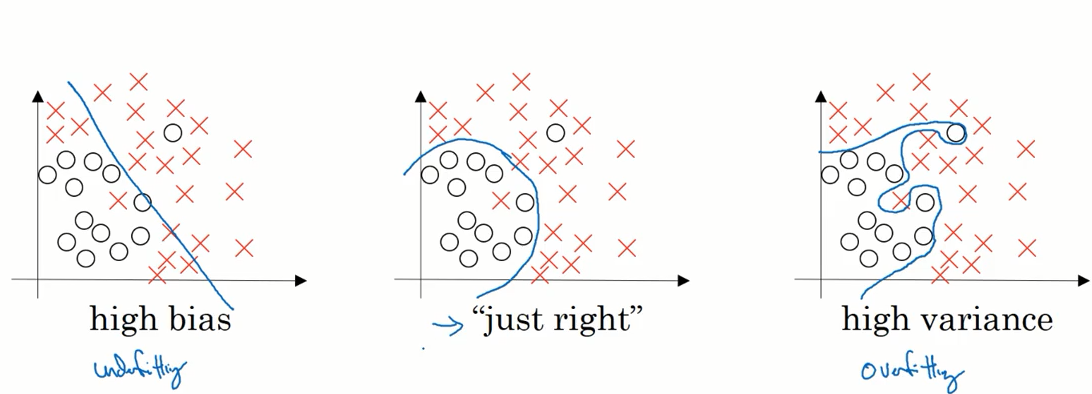
在多位空间数据中绘制数据和可视化分割边界无法实现,我们可以通过几个指标来研究方差和偏差。
下面举个例子:
在判断是否是猫的问题上,人类可以做到几乎不出错,即错误率约为 0% 。当算法在训练集上准确率错误率为 1% 时,我们认为算法表现良好。如果算法在训练集上表现较好,而验证集上表现较差,那么我们称之为 高方差。
下面的表格给出了错误率与方差偏差之间的关系。
| Test set error | Dev set error | bias/variance |
|---|---|---|
| 1% | 11% | high variance |
| 15% | 16% | high bias |
| 15% | 30% | high bias & high variance |
| 0.5% | 1% | low bias & low variance |
正则化
有关正则化的先关内容已在机器学习的课程中详述过,这里不再记录。
L1 正则化
如果使用 L1 正则化,w 最终会是稀疏的,即矩阵中会有很多的 0 。
正则化项:
$$
\large
\frac{\lambda}{2m}||w||_1=\frac{\lambda}{2m}\sum_{j=1}^{n_x}|w_j|
$$
L2 正则化
目前人们更倾向于使用 L2 正则化
正则化项:
$$
\large\frac{\lambda}{2m}||w||^2_2=\frac{\lambda}{2m}\sum_{j=1}^{n_x}w_j^2 = \frac{\lambda}{2m} w^Tw
$$
这里为什么不正则化参数 b 呢?其实可以加上参数 b ,但因为参数 w 通常是一个高维参数矢量已经可以代表搞偏差的问题,w 已含有很多参数,我们不可能拟合所有参数,而 b 只是单个数字,加或不加其实并没有太大的影响。
Dropout(随机失活) 正则化
dropout 是一种另一种实用的正则化方法,
dropout 会遍历网络的每一层,并设置消除神经网络节点中的概率。
下图中我们设置每个节点保留和消耗的概率都是 0.5 ,在消除掉某些节点之后我们就得到了一个节点更少,规模更小的网络,然后使用反向传播算法进行训练,这时网络节点精简后的一个样本。
对于其它样本,依旧按概率随机消除节点。对于每个训练样本,我们都将采用一个精简后的神经网络来训练它。
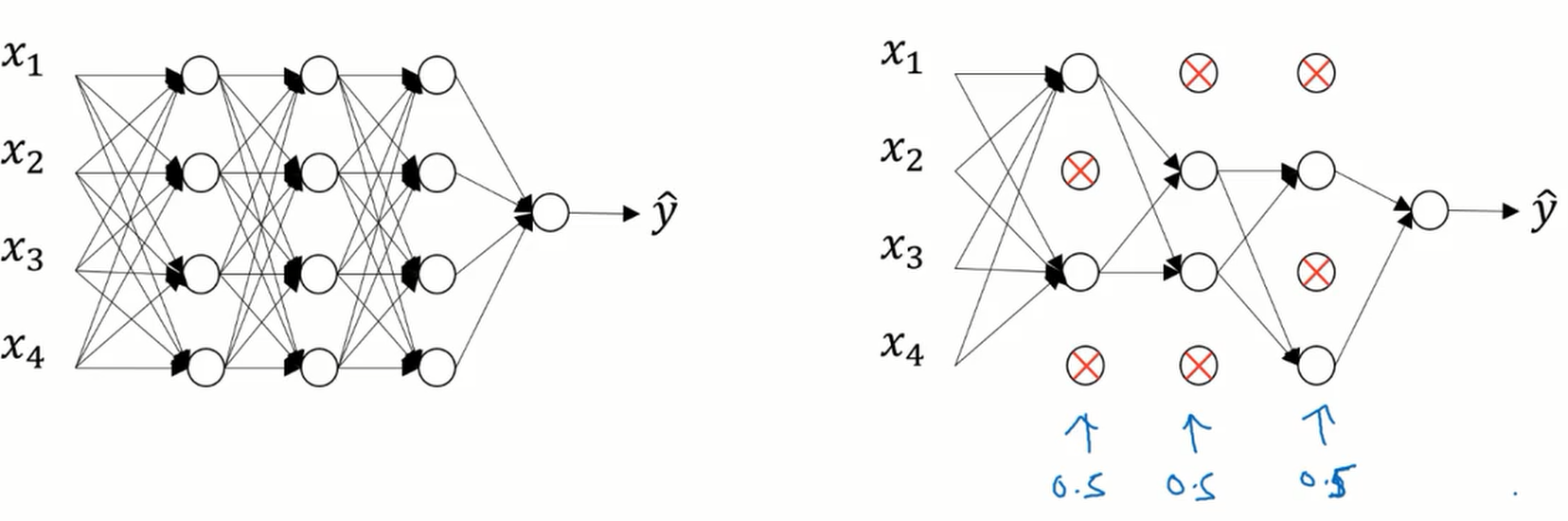
在测试阶段的时候不应该使用 dropout ,否则的话我们每次测试的结果预期值都不相同。
如何理解 dropout ?
从直觉上来理解,因为每次消除的节点不相同,所以神经网络不能依赖于任何一个单独的节点,它将权值分散在各个节点上。
参数扩增
很多时候增加数据集的代价很高,我们可以通过人工的方式扩增数据集。比如对于图片的数据集,我们可以对其做水平翻转,或是增加噪声等等。
early stopping
从下图中我们可以看到,随着迭代次数的增加训练集的误差逐渐减少,而测试集的误差在开始时下降,随后开始增加。我们只要在测试集的误差开始增加之前停止训练,就可以防止出现过拟合的情况。
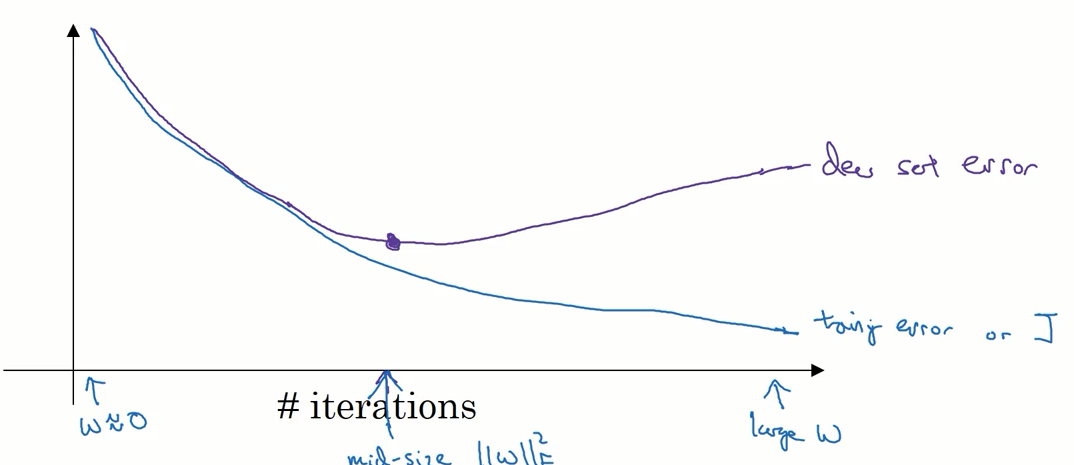
但这个方法也有缺点,即训练集的误差无法降到最小。
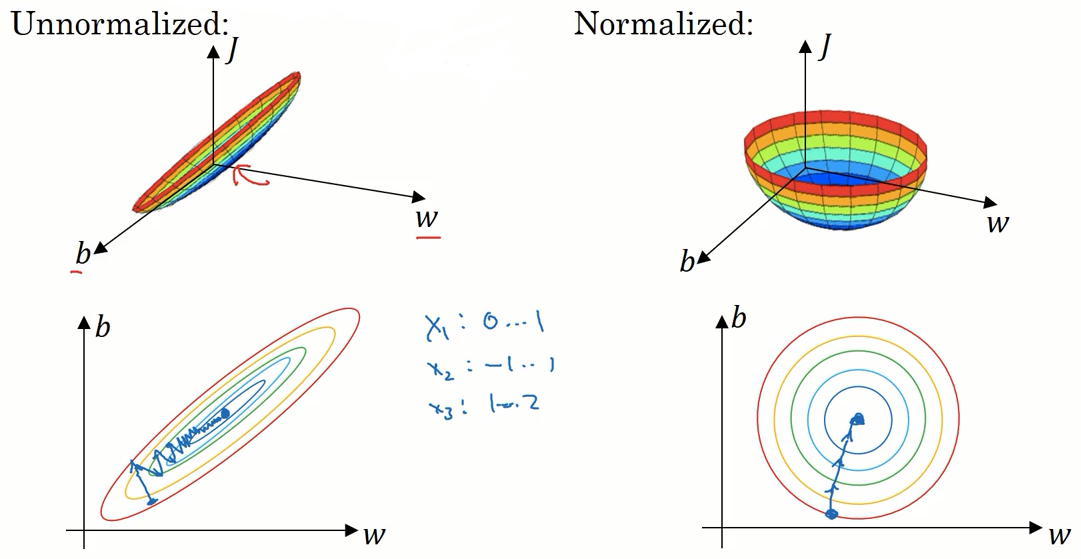
归一化输入
归一化输入是加速训练神经网络的一种方法。
归一化输入需要两个步骤,第一步是 零均值化。
$$
\mu = \frac{1}{m}\sum_{i=1}^m \
x = x - \mu
$$
这一步相当于对数据集做了移动
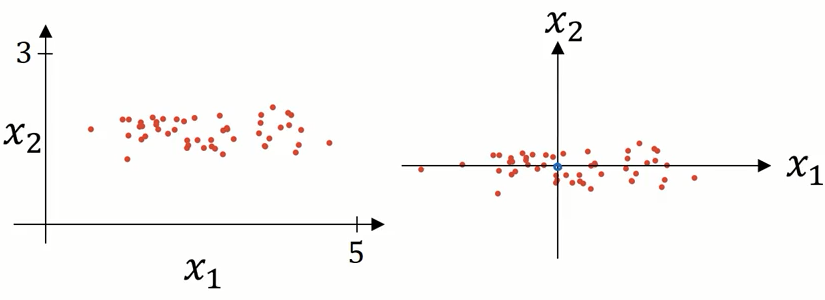
第二步是归一化方差。
从上面的图中可以看出,特征 x1 的方差比特征 x2的方差要大很多
$$
\sigma^2 = \frac{1}{m}\sum_{i=1}^mx^{(i)}**2 \
x \quad/= \sigma^2
$$
最后的结果如图所示
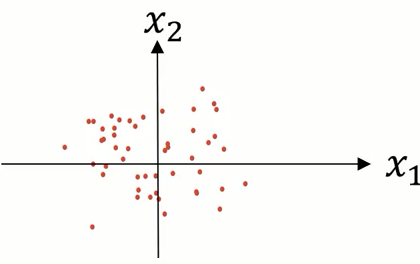
注意,应该用同一组 $\mu$ 和 $\sigma^2$来调整 训练集和测试集。
经过归一化的数据,在执行梯度下降时速度更快。
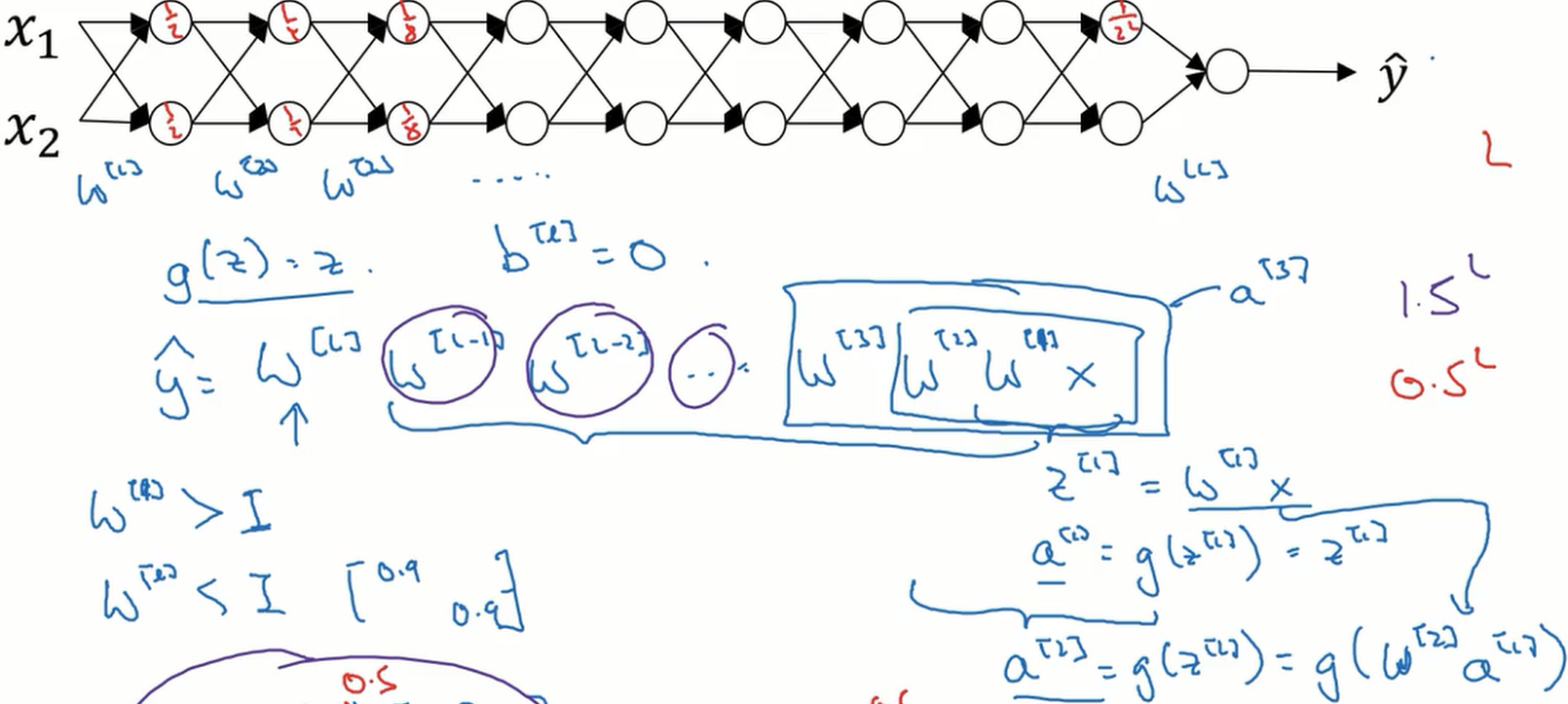
梯度消失与梯度爆炸
梯度消失与梯度爆炸是指当训练神经网络时,梯度或坡度会变得很大,或非常小,甚至以指数的形式变小。
如下图,当网络的层数很深时,梯度层层相乘,如果梯度比 1 大一点点,最后也会变得非常大。相反,如果梯度比 1 小一点点,最后也会变得非常小。
权重初始化
虽然不能从根本上解决梯度消失和梯度爆炸的问题,但以合适的方法初始化权重可以减少其影响。
假设某层输入特征数量为 n,我们可以将权值矩阵初值设置为 随机值* $\sqrt{\frac{1}{n}}$
$$
\large
W^{[l]} = np.random.radn(shape) * np.sqrt(\frac{1}{n^{[l-1]}})
$$
梯度检验
如何判断反向传播正确的工作了呢?可以使用下面的方法对其进行检验。
核心思想是使用一个导数计算的近似公式求出导数,并与反向传播算法得出的结果进行比较,在一定的误差范围内,我们就可以认为反向传播算法正常工作。
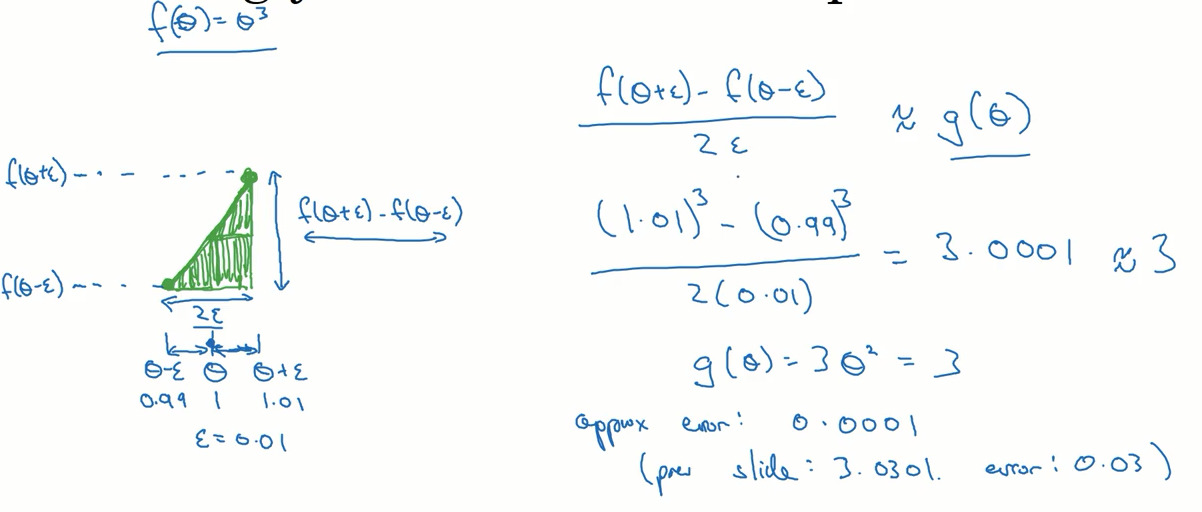
实施注意事项
- 不要用在训练中,仅仅在调试时使用。
- 如果梯度检验失败,需要详细检查相关项
- 注意正则化
- 不能与 dropout 同时使用
- 如果效果不理想,可以尝试重新训练

