本文内容是 deep_learning.ai 微专业的第三门 《构建机器学习项目》第一周的课程。
这门课的内容与如何更快速高效地优化机器学习系统有关。
正交化
搭建机器学习系统的挑战之一是我们可以尝试和修改的东西太多了,比如说有许多的超参数可以调整。
许多高效的机器学习专家非常清楚要达到某种效果需要调整那些参数,这个过程我们称为正交化。
看下面的例子:
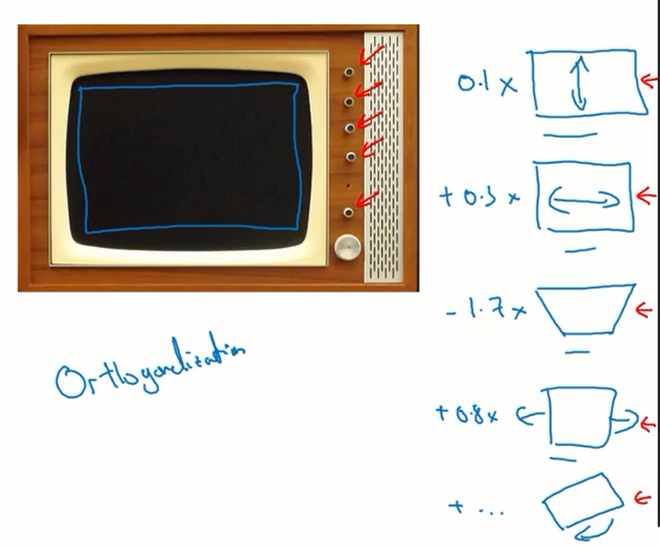
在老式的电视中有许多旋钮可以调整电视的画面,如有些旋钮可以调节画面的横向宽度,有的可以调节纵向的宽度等等。这些旋钮都独立的负责某一功能,这样我们就可以通过调节不同的旋钮达到自己想要的效果。但如果某个旋钮同时具备了两个功能,那么我们在调节的时候可能并不会那么容易。
这就是正交化的一个简单的例子。
同样的,在机器学习系统中我们也可以设置类似的“旋钮”来实现不同的独立的功能。例如可以设置某个“旋钮”可以调节训练集的大小,或是切换不同的优化算法等等。
单一数字评估指标
在前面提到过的猫分类器,我们可以通过 precision 和 recall 这两个指标来评价一个🐱分类器的好坏。
但如果我们有多个🐱分类器的话如何来评价它们的优劣呢?我们需要一个单一数字评估指标,在这里我们将 precision 和 recall 两个指标结合起来得到一个新的指标 F1 Score(可以理解为 precision 和 recall 的某种平均值) , 这样我们就可以通过 F1 Score 这个指标来快速的比较不同分类器之间的好坏了。

满足和优化指标
有时候要把我们所有顾及的事情结合成单一数字评估指标是不容易的,在这样的情况下,设置满足和优化指标是很有用的。
| classifier | accuracy | runtime |
|---|---|---|
| A | 90% | 80ms |
| B | 92% | 95ms |
| C | 95% | 1500ms |
假设我们决定很看重分类器的 accuracy 和 runtime 两个指标,我们可以把这两个指标以某种方式结合成单一数字评估指标。但是这样并不是最好的方法,因为就 runtime 这一指标而言,只要其值小于 100ms,那么 80ms 和 95ms 对用户来说并没有太大的差别,但用户对 accuracy 的要求更高。所以我们可以将 runtime 设置为满足指标,而将 accuracy 设置为优化指标。
人的表现
我们在评估一个机器学习系统的性能时,常常会将其与人类的表现进行对比。这是为什么呢?
这里需要提到贝叶斯最优错误率,贝叶斯最优错误率一般认为时理论上可能达到的最优错误率。也就是说没有任何办法可以设计出一个 x 到 y 的函数可以使它的准确度能够超过一定的标准。而人类在某些方面十分擅长,几乎接近了贝叶斯最优错误率。所以在某些时候可以用人类的表现来估计贝叶斯最优错误率。
另一个方面是当机器学习系统准确率在超过人类的表现之后,想要在提升准确率就会变得非常缓慢。这有两个原因,第一个就是上面提到的人类的表现已经很接近贝叶斯最优错误率了。第二个原因是当机器的准确率未达到人类的表现时有很多工具可以帮助机器提升准确率,例如可以让人类对数据进行标注等。而当机器的准确率超过人类的表现后则没有相应的工具了。
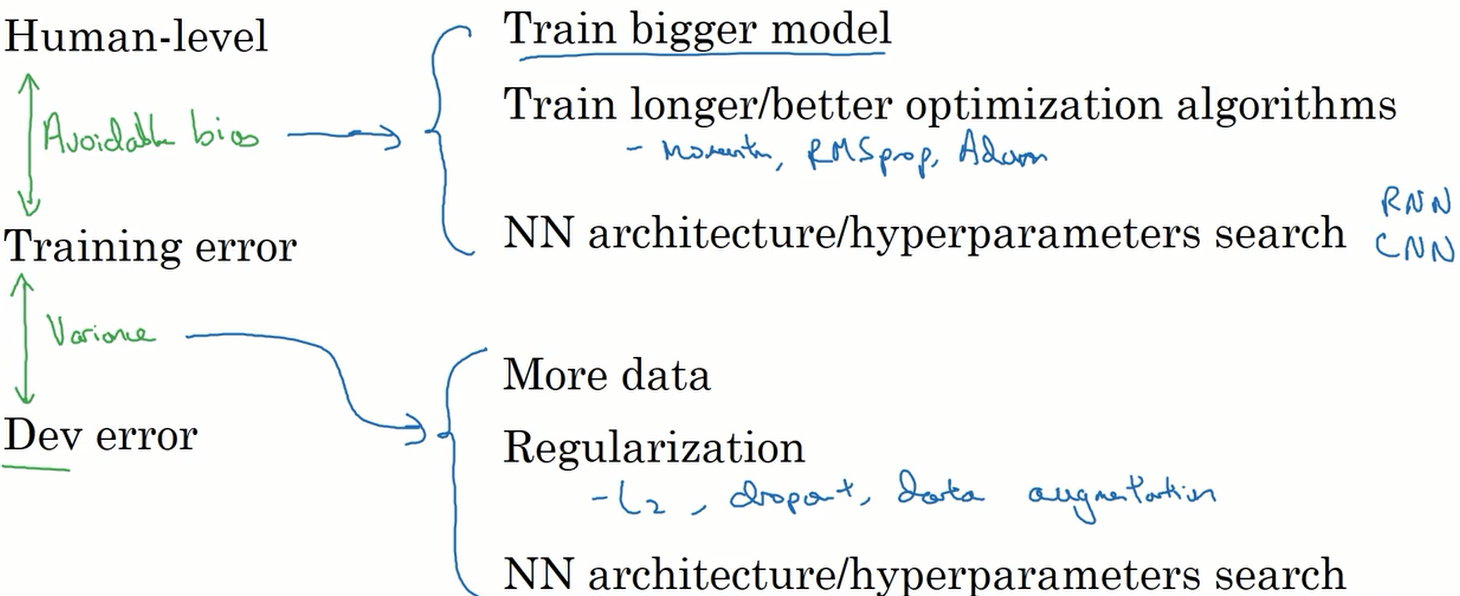
可避免偏差
| Humans($\approx$ Bayes) | 1% | 7.5% |
|---|---|---|
| Training error | 8% | 8% |
| Dev error | 10% | 10% |
我们将贝叶斯错误率和训练集上的错误率之差称为可避免偏差。
在上面左边的例子中可避免偏差为7%,而训练集与开发集的方差为 2%,在这样的时候我们应考虑减少可避免方差。
在右边的例子中可避免偏差为 0.5%,而训练集与开发集的方差仍为 2%,所以我们应该将精力放到减少方差上。
改善你的模型表现