本周介绍了一些经典的网络结构。
经典网络
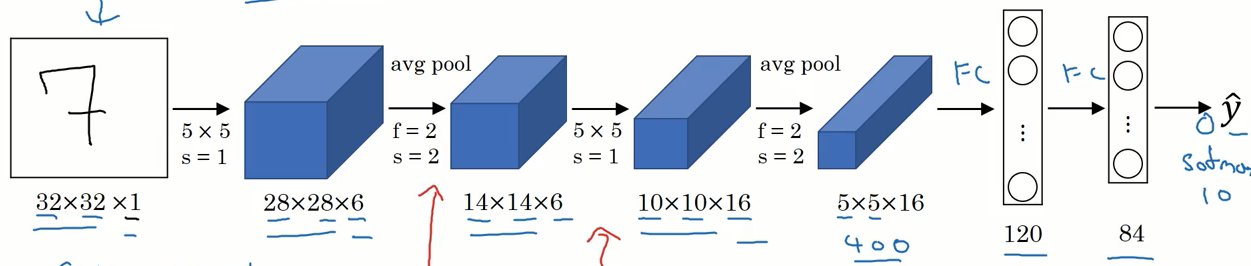
LeNet
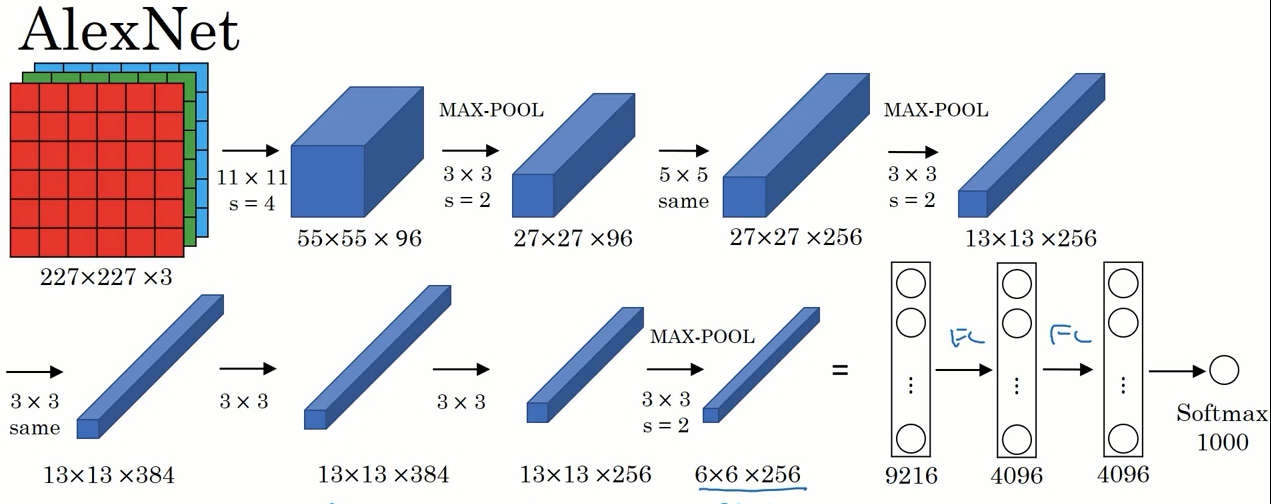
AlexNet
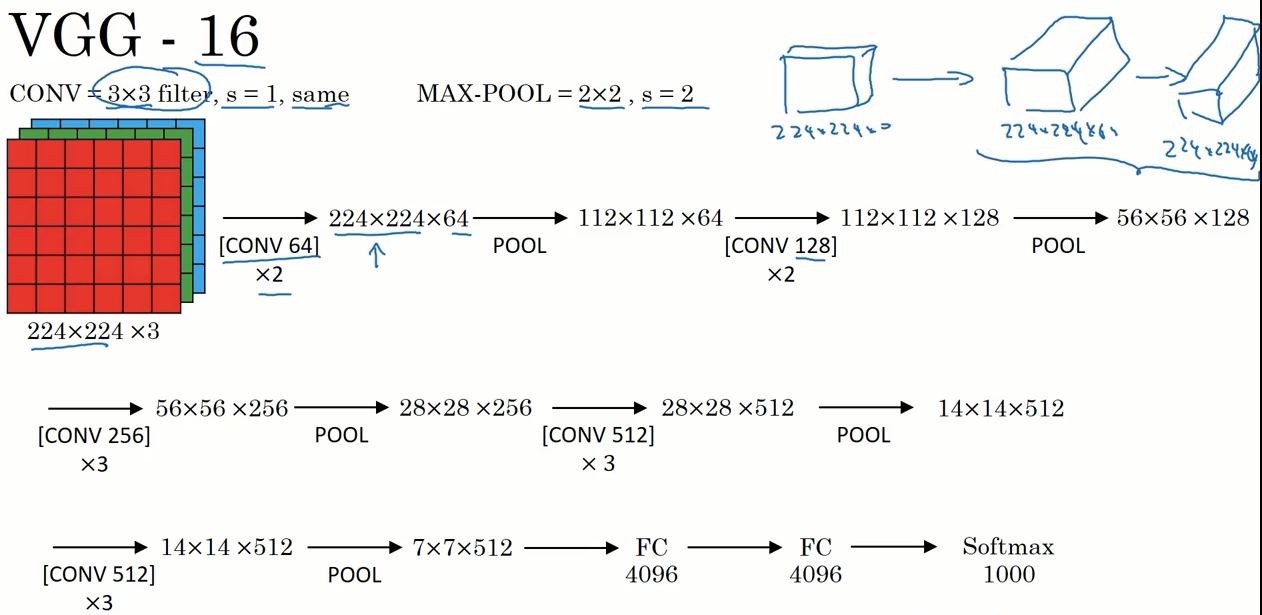
VGG16
残差网络
非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸的问题。这节课我们学习跳远连接,它可以从网络的某一层获取激活值,然后迅速反馈给另外一层,甚至是神经网络的更深层。使用跳远连接我们可以构建训练深度网络的残差网络。
残差网络是由残差块构成的,下图是一个残差块的结构。
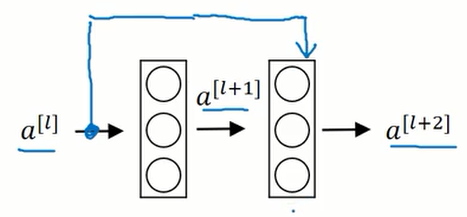
忽略上图中蓝色的箭头线,那么这两层的激活值传递过程如下:
$$
\large
z^{[l+1]}=W^{[l+1]} a{[l]} + b^{[l+1]} \\
a^{[l+1]}=g(z{[l+1]}) \\
z^{[l+2]}=W^{[l+2]} a{[l+1]} + b^{[l+2]} \\
$$
加上蓝色的箭头线后,传递过程变成了下面的样子(只有最后一个公式有变化):
$$
\large
a^{[l+2]}=g(z{[l+2]} + a^{[l]})
$$
这就相当于激活值$a$走了一个捷径,或者说是进行了跳远连接。
在下图中将一个普通的网络进行跳远连接,这样就形成了一个残差网络。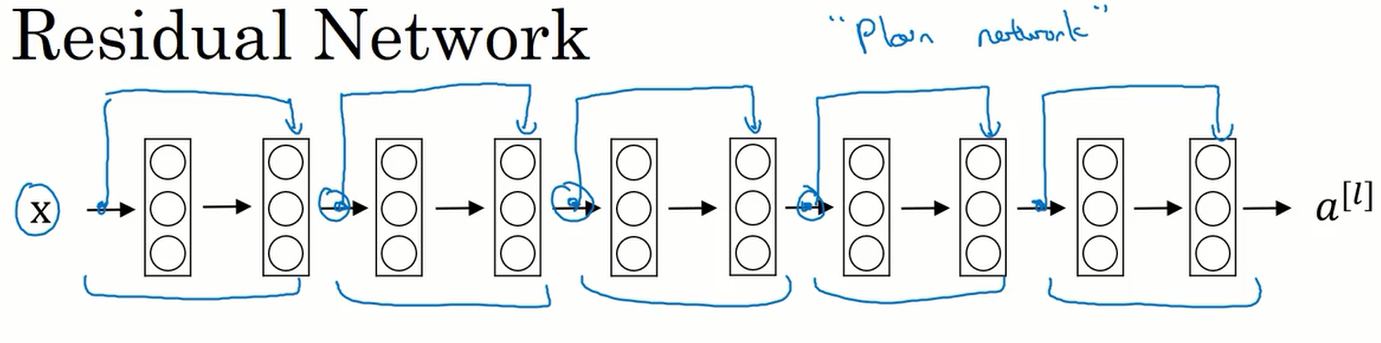
残差网络 为什么有用呢?
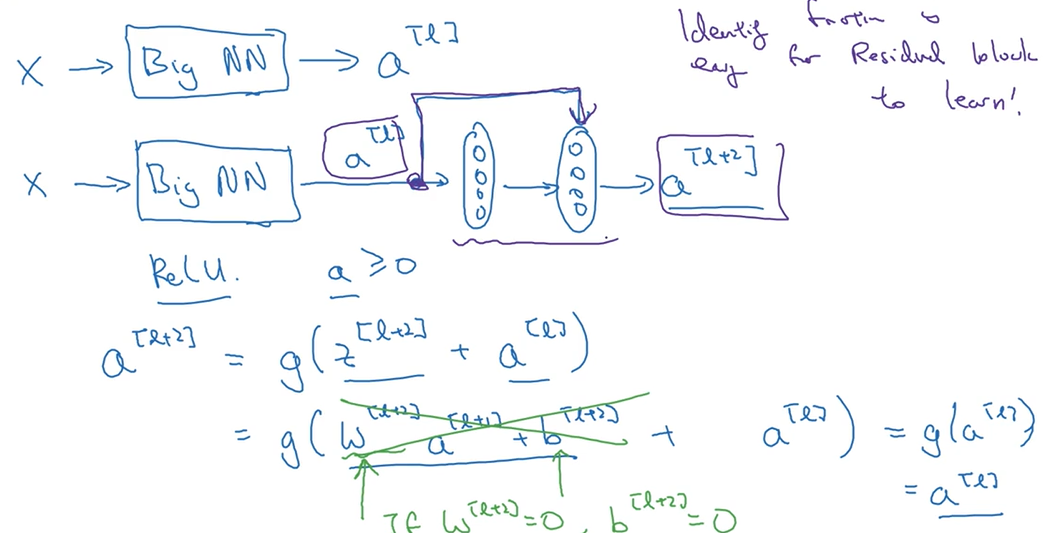
上面有两个神经网络,我们在其中一个的末尾衔接上一个残差块。再将最后一个激活值的传递公式写出。由于正则化等的使用,$W^{[l+2]}$ 和 $b^{[l+2]}$ 可能会接近于 0 。这样的话 $a^{[l+2]}$ 就等于 $g(a^{[l]})$(这里使用 ReLU 激活函数) ,因为这里$a^{[l]}$ 为非负值,所以就可得到 $a^{[l+2]}=a^{[l]}$。
结果表明,残差块学习这个恒等函数残差块并不难,这意味着即使给网络增加了两层,但它的效率也不会降低。虽然多了两层,但所做的也只是将$a^{[l]}$的值赋给$a^{[l+2]}$。
但我们的目的并不只是保持网络的效率不变,我们还要提高它的表现。想象一下,如果这两层网络学习到了有用的东西,那么它就可以表现得比恒等函数更好。
网络中的网络/1x1 卷积
1x1 卷积的作用简单的说就是给神经网络添加一个非线性的函数,从而减少或保持输入层中的信道数量,当然也可以增加信道的数量。
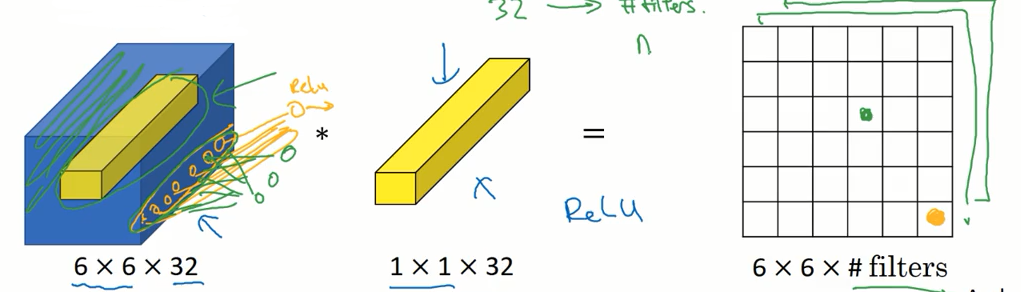
我们用这个 1x1x32 的过滤器处理 6x6x32 的输入,即用过滤器遍历输入的 36 个单元格,与过滤器中对应的数字相乘并求和,在经过一个 ReLu 函数,输出到最后的矩阵中。这样就得到了一个 6x6x1 的输出。以此类推,如果使用两个 1x1x32 的过滤器,就可以得到 6x6x2 的输出。
这样就达到了修改信道数量的目的。
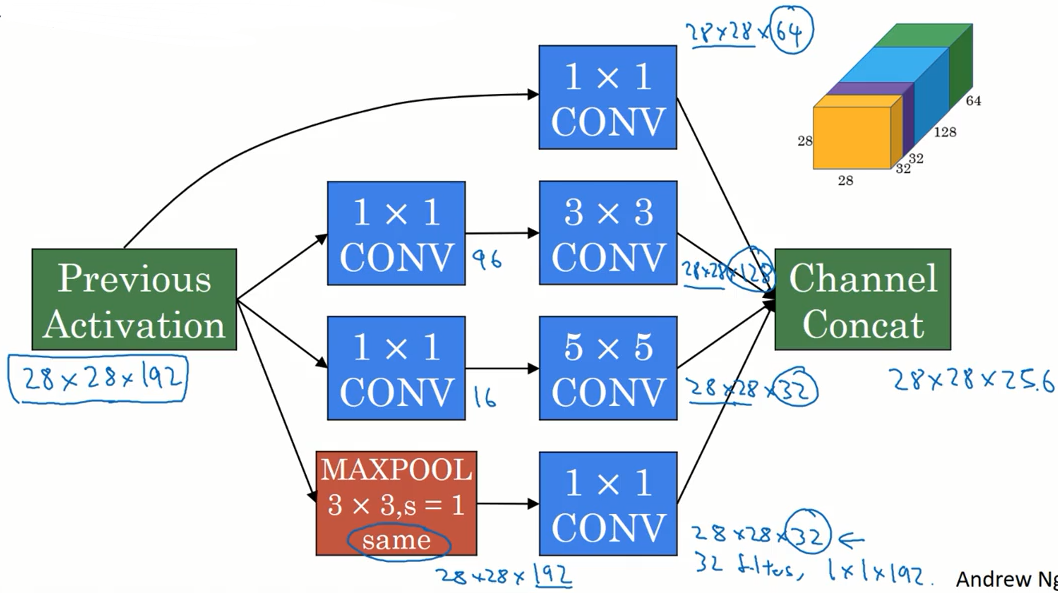
Inception 网络
在设计神经网络的时候,需要选择过滤器的大小 1x3,3x3 或 5x5,又或是使用 池化层。 Inception 网络的作用就是代替你做出这些选择,虽然网络的结构变复杂了,但是效果却变好了。
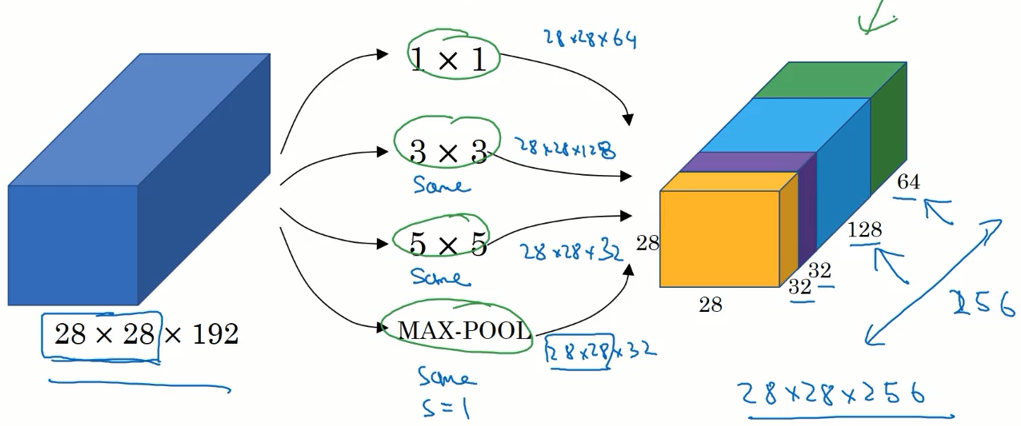
我们对输入层进行 1x1 ,3x3 ,5x5 卷积 和 最大池化处理,并且将结果堆叠起来得到最后的输出,这样就可以让网络自己学习使用哪个参数。
但这样的缺点也是显而易见的,训练网络所需要的计算量大大的增加了。前面讲的 1x1 卷积 可以帮助我们减少计算量。
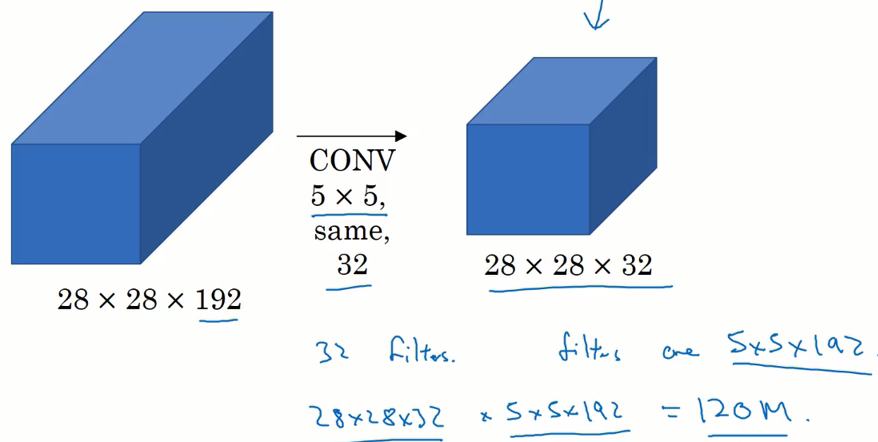
下图是上面 5x5 过滤器的计算过程,这里一共需要进行 1.2 亿次乘法运算。
而在中间加入一个 1x1 的卷积之后,只需要进项 0.12 亿次乘法运算,并且输出的结果尺寸不变。
这个 1x1 的卷积层 也被称为瓶颈层。
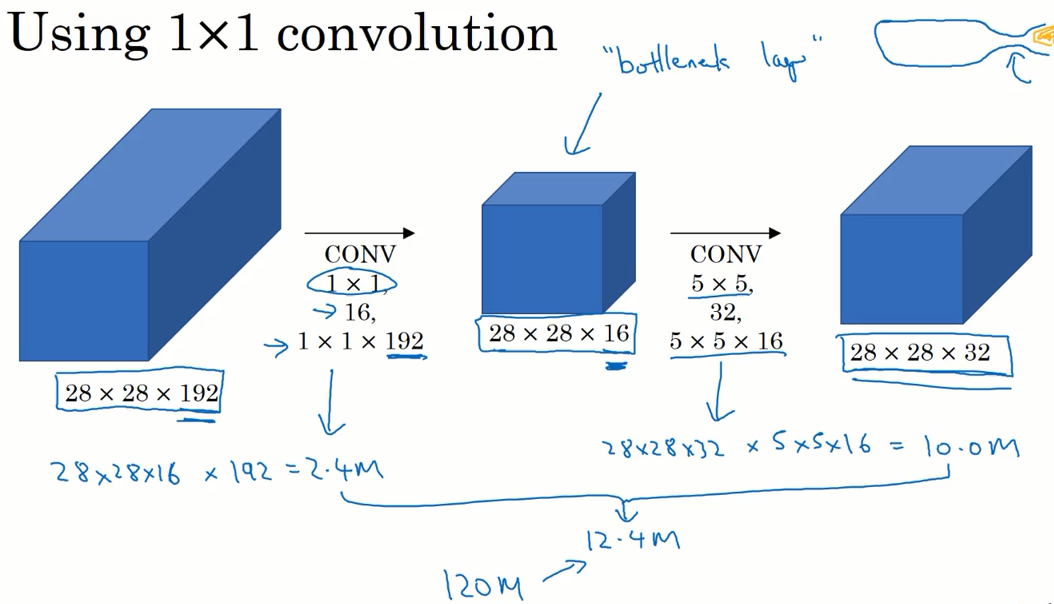
也许有人疑问,这样的作法是否会降低神经网络的性能,事实证明只要瓶颈层设置的合理,性能就不会受到影响。
有了以上的铺垫,我们就可以搭建 Inception 网络了。
下图是一个 Inception 模块,将多个这样的模块拼接起来就得到了 Inception 网络。